Источник: @karpathy
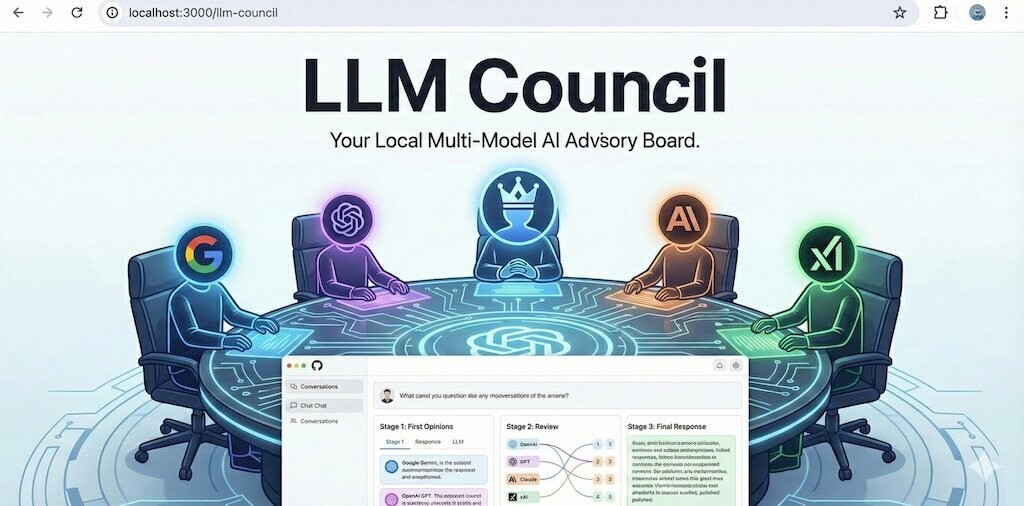
Один из ключевых специалистов в области ИИ Андрей Карпатый рассказал в X, что сделал с помощью вайб-кодинга веб-приложение “LLM Council” — оно выглядит «как ChatGPT», но каждый запрос отправляется сразу нескольким моделям. Например, GPT 5.1 от OpenAI, Gemini-3-pro-preview от Google, Claude-Sonnet 4.5 от Anthropic и Grok-4 от xAI.
Затем все модели смотрят анонимные ответы друг друга, оценивают их и ранжируют. После назначенный «председатель» (“Chairman LLM”) объединяет все ответы и принимает финальное решение.
Карпатый отметил, что часто модели «неожиданно» признают, что ответ другой LLM лучше их собственного. Это может быть «интересной стратегией» для более общей оценки моделей.
Например, исследователь читал книгу и обсуждал её вместе с “LLM Council”: модели выделили ответы GPT 5.1 как лучшей, а Claude — как худшей, остальных разместили между ними. Сам Карпатый не совсем согласился с этой оценкой: он считает GPT 5.1 слишком многословным, Gemini 3 — более структурированной, а Claude — слишком кратким.
Источник: